
Claude Code 老在失忆?用 claude-mem 把项目记忆存下来
Claude Code 默认每开一次新会话都得重讲一遍项目结构和历史决策。claude-mem 这个开源插件用 hooks + SQLite 自动记录工具调用和会话摘要,下次开窗直接接上次进度——给个人开发者省的不是几分钟,是几十块的 token 费。
用过 Claude Code 的人都会遇到一个尴尬场景:刚花十分钟教会它"这是个 Next.js 项目、API 在 src/app/api、测试命令是 pnpm test",今天的活儿干得很顺。结果第二天打开新会话,它又像个新员工一样问你:"这是什么项目?后端用的什么?"
Token 费没少花,重要的活儿没多干,全在重复解释里耗掉了。
最近社区里一个开源项目专门治这个病——claude-mem,作者是 thedotmack。今天这篇文章,就把它的来龙去脉讲清楚,顺便说说哪些场景值得装、哪些可以观望。

Claude Code 默认状态的"金鱼记忆"
Claude Code 的单次会话很强,但开发本身是跨天、跨任务的活儿。一旦关掉窗口,下次再开就是"白纸状态",常见的几个翻车场景:
项目结构讲了又讲。 比如你昨天告诉它"前端 Astro、后端 Hono 跑在 Cloudflare Workers、数据库是 D1"。新会话开始,它不知道你用的什么栈,要么乱建议、要么又来一轮试探。
昨天否掉的方案,今天又被推荐一遍。 比如你和 Claude 讨论过"为什么不用 JWT 而是 session + Cookie",并且写进了代码。明天新窗口里,它可能又开始给你提"建议改成 JWT"。讨论过的坑,等于白讨论。
Bug 排查链路断掉。 上次已经定位到某个 worker 的重试逻辑有问题,跑过几条命令、查过几个日志。隔天接着修时,它不记得查到哪一步,只能从头 grep、从头读代码。
官方倒是有 CLAUDE.md 让你写项目规则,但 CLAUDE.md 更适合写"稳定不变的事实"——技术栈、目录约定、禁止动的模块。它装不下的是"过程性记忆":临时调试发现、被否的方案、上次干到哪一步。
claude-mem 要补的就是这一块。
claude-mem 到底是什么
一句话:它是 Claude Code 的一个开源插件,用生命周期 hooks 自动记录你和 AI 干了什么,下次开会话时把相关上下文重新注入回去。
更具体地说,它不是个"聊天记录保存器"。它把每一次工具调用(读文件、改文件、跑命令)都捕获下来,用 AI 压缩成结构化的 observations(观察)和 session summaries(会话摘要),存到本地 SQLite 数据库里。下次启动 Claude Code 时,相关项目的近期摘要会自动出现在新会话上下文里——你不用动嘴,AI 就知道"昨天我们干到这一步了"。
值得注意的是,它现在也支持 Codex、Gemini CLI、OpenCode 等场景,但 Claude Code 仍是核心阵地。本文按 Claude Code 用法来讲。
核心机制:它是怎么做到的
走一遍内部流程,理解了机制后续踩坑会更清楚:
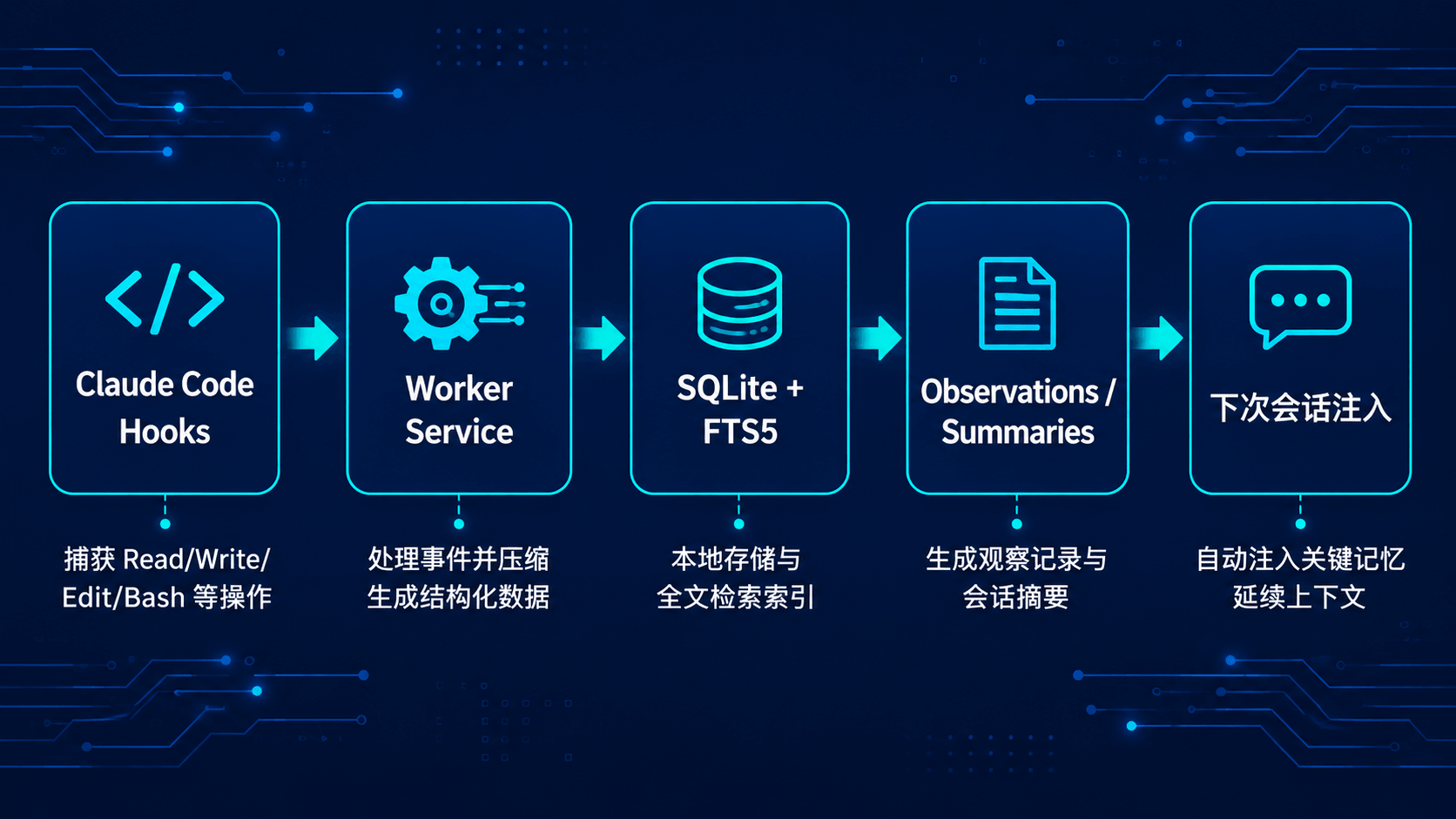
- 安装时注册 hooks。 把自己挂到 Claude Code 的
SessionStart、UserPromptSubmit、PostToolUse、Stop等生命周期事件上。 - 新会话启动时读取旧记忆。
SessionStart触发后,后台 worker 启动,把当前项目最近的 observations 和 session summary 注入到新会话。 - 运行过程中持续捕获。 你输入的 prompt、Claude 用的
Read/Write/Edit/Bash/Glob/Grep工具,每次调用都被记下来。 - 后台 worker 异步压缩。 把零散的 tool 调用打包成结构化 observation——包含标题、副标题、叙述、事实、概念、涉及的文件等。会话结束时(
Stophook)生成 session summary,包括"请求""调研""学到""完成""下一步"几个字段。 - 存到本地 SQLite + FTS5。 数据在
~/.claude-mem/claude-mem.db,自带全文搜索。日志、设置、worker pid 都在~/.claude-mem/目录下。 - 按需召回。 它不会把所有历史一次性塞进上下文。Claude 用 MCP 工具按需搜索:先
search拿轻量索引,再timeline查上下文,最后get_observations拉详细内容。官方称这种"渐进披露"比传统 RAG 省 token。
技术上可以这样一句话概括:
Claude Code hooks 捕获行为 → SQLite/FTS5 存储 → worker 用 AI 压缩成 observations / summaries → 新会话自动注入摘要 → 需要深挖时用 MCP 搜索按需召回
安装与日常使用
官方推荐两种装法:
# 方式 1:直接通过 npx
npx claude-mem install
# 方式 2:在 Claude Code 内通过 plugin marketplace
/plugin marketplace add thedotmack/claude-mem
/plugin install claude-mem
踩坑提醒:不要用 npm install -g claude-mem。那只装了 SDK,不会注册 plugin hooks,也不会启动 worker。装完发现"啥反应都没有"通常就是这个原因。
装好之后基本不用管它。worker 会在第一次 SessionStart 时自动起来,后续整个写记忆/读记忆的过程都是后台进行。你日常感知到的只有一件事——新窗口开起来时,最上方会带一段"最近会话上下文"。
要查询历史时,直接用自然语言对 Claude 提问就行:
What bugs did we fix last session?
How did we implement authentication in this project?
What changes were made to worker-service.ts last week?
Claude 会自己调 search / timeline / get_observations 这三个 MCP 工具去查。
想直接看原始数据?SQLite 文件就在本地:
sqlite3 ~/.claude-mem/claude-mem.db
几个值得提前知道的特性
<private> 标签:如果某段对话不想被持久化,包一层:
<private>
这段不会被存进 claude-mem 数据库
</private>
Claude 当前会话还能看到,但 worker 在写入前会过滤掉。适合临时贴的密钥、临时讨论的敏感方案。
导出/导入:官方提供脚本能把指定项目的记忆导出成 JSON:
npx tsx scripts/export-memories.ts "my-project" my-project-memories.json
npx tsx scripts/import-memories.ts my-project-memories.json
注意导出文件是明文 JSON,分享前自己审一遍有没有敏感信息。
Worker 管理命令:日常用不到,排查问题时有用。worker:start / :stop / :restart / :logs / :status 各干各的。
真正适合谁用
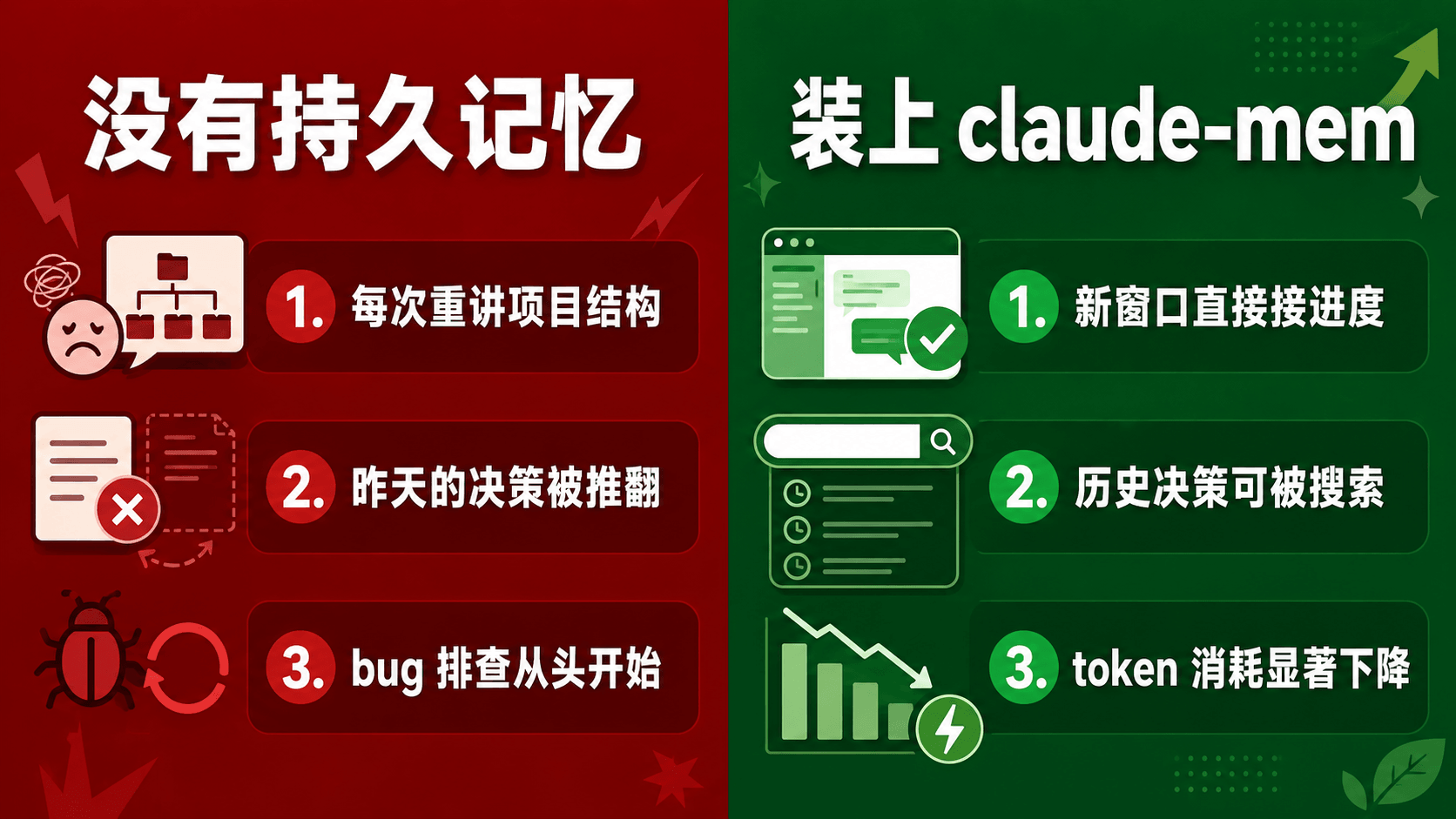
不是所有 Claude Code 用户都需要。装它之前先对照看看自己是不是这几类人:
- 长期维护同一个项目的独立开发者。 越复杂的项目历史上下文越值钱。
- 真的把 Claude 当干活工具的人。 如果只是偶尔问问语法,收益不大;但你让它读代码、改代码、跑测试、修 bug,observation 会越攒越值钱。
- 跨天连续开发同一功能的人。 比如做认证、做支付、做后台任务这种需要好几天迭代的活。
- 讨厌重复解释项目背景的人。 最直观的收益就是少打字。
- 靠 AI 编程做副业的人。 时间就是钱。少用 30% token 把项目重新介绍一遍,长期省下的就是真金白银。
反过来,以下场景就别装了:
- 一次性脚本、临时实验性项目,没什么"过程"需要记。
- 涉及高敏感数据的项目(医疗、金融、个人 PII),自动捕获的范围你不一定都能控制。
- 主力还在用其他 AI 编程工具的人,目前的最佳收益还是绑在 Claude Code 上。
它的局限要心里有数
第一,它不是完美记忆。压缩 = 信息损失。关键、长期不变的规则仍然建议写进 CLAUDE.md,别全押在 claude-mem 上。
第二,消耗额外资源。worker 要常驻,observation 要靠模型压缩,会增加一点 API 调用。
第三,记忆质量需要维护。项目历史里如果有过期方案、废弃决策、临时调试日志,时间一长 Claude 可能引用旧记忆。建议每个版本节点或重大重构后导出备份一次,并定期清理无效条目。
第四,和官方 Auto memory 有重叠。Claude Code 2.1.59+ 自带 Auto memory,会让 Claude 自己往项目目录写 MEMORY.md 和拆分的 topic 文件。两者并存不冲突——Auto memory 偏稳定规则与高级总结(前 200 行/25KB 每次会话都加载),claude-mem 偏全过程行为日志与可搜索召回。
同类方案怎么选
简单做个对比:
| 方案 | 来源 | 维护方式 | 适合内容 | 缺点 |
|---|---|---|---|---|
CLAUDE.md |
Claude Code 官方 | 手写 / /init 后维护 |
稳定规则、目录约定、代码风格 | 不适合记录"过程" |
Auto memory / MEMORY.md |
Claude Code 官方 | Claude 自动写 | 重要决策、约定、用户偏好 | 粒度较粗 |
| claude-mem | 第三方开源 | 自动捕获 hooks | 工具调用、调试链路、最近进展 | 噪音、资源、隐私需管理 |
| 自建 MCP memory server | 你自己 | 自己设计存储/召回 | 团队级、企业级、可对接私域知识库 | 开发成本高 |
一句话总结:
CLAUDE.md是"项目说明书",Auto memory 是"AI 自己写的便利贴",claude-mem 是"自动生成的开发日志 + 可搜索记忆库",自建 MCP server 是"自己造一个记忆系统"。
写在最后
claude-mem 不是"Claude Code 必装神器"。
更稳的判断是:如果你只是偶尔用 Claude Code 问几个代码问题,CLAUDE.md + 官方 Auto memory 大概率够用;但只要你长期用 Claude Code 参与真实项目开发——尤其是跨天修 bug、做重构、维护复杂项目——claude-mem 的自动捕获和历史搜索会肉眼可见地降低你"重复解释项目背景"的成本。
对于把 AI 编程当主力的人,省下的不只是几分钟,是一份长期复利。
如果文章对你有帮助,欢迎请作者喝杯咖啡

评论(0)